
Sudden AWS EC2 performance issue
If your EC2 virtual private server instance performance has suddenly dropped off a cliff edge then it may be worth checking the ‘Average Write Latency’ metric. This metric shows the time it takes to write to your hard drive. The lower the latency, the faster the write, the sooner your server can move onto something else. This is a very important metric as a low latency means better performance and the opposite is also true.
The issue
We recently had a sudden and unexpected performance issue with an EC2 Linux instance and diagnosed the issue to the read / write latency of the hard drive. The server needed to use the hard drive but the latency was slowing everything down.
The cause
Further investigation revealed a problem with the gp2 burst-bucket. AWS designed their SSD hard drives to have bursty I/O up to 3000 per second and then replenish it during quieter times at a rate of 3 per configured GB per second. But we had completely run out of burst with no sign of replenishment, causing the high write latency.
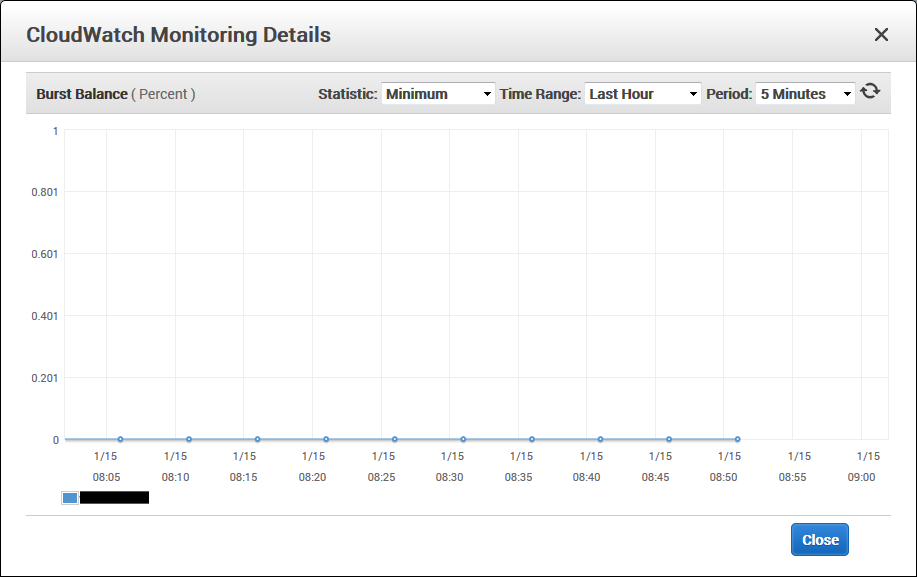
AWS EC2 Burst Balance
The Burst Balance was at zero leaving us with no available I/O per second causing the write latency to increase and slow the server down.
The solution
We decided to stop the instance and start it again. This is different to a reboot as the instance is started in an undefined location in the data centre and will likely use different hardware.
Hey presto, once the server had come back on-line and the metrics starting recording again we could see an incredible drop in latency and once the server had run its start-up processes, it returned to return normal.
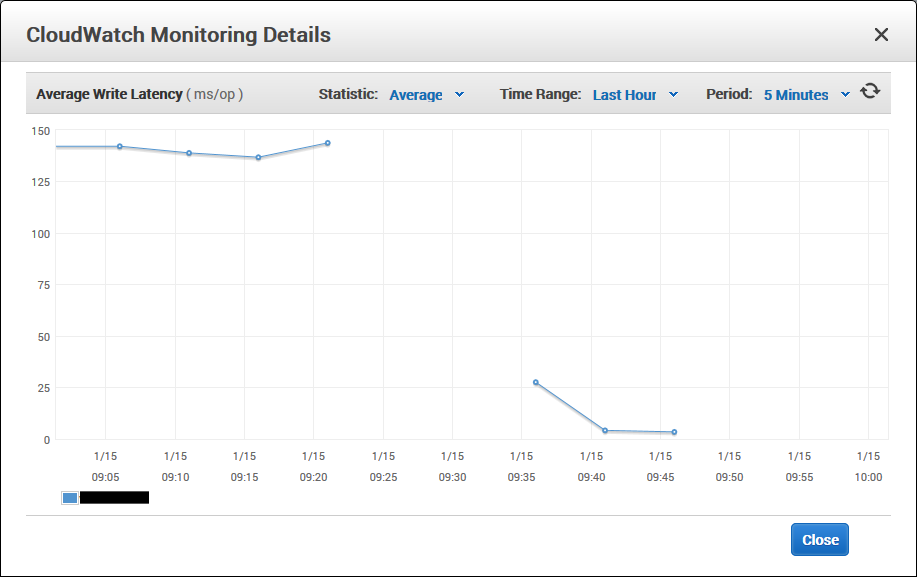
AWS EC2 Write Latency
The write latency before the instance stop / start was around 143ms per operation. Once the stop / start had been performed the latency dropped to 1.27ms per operation.
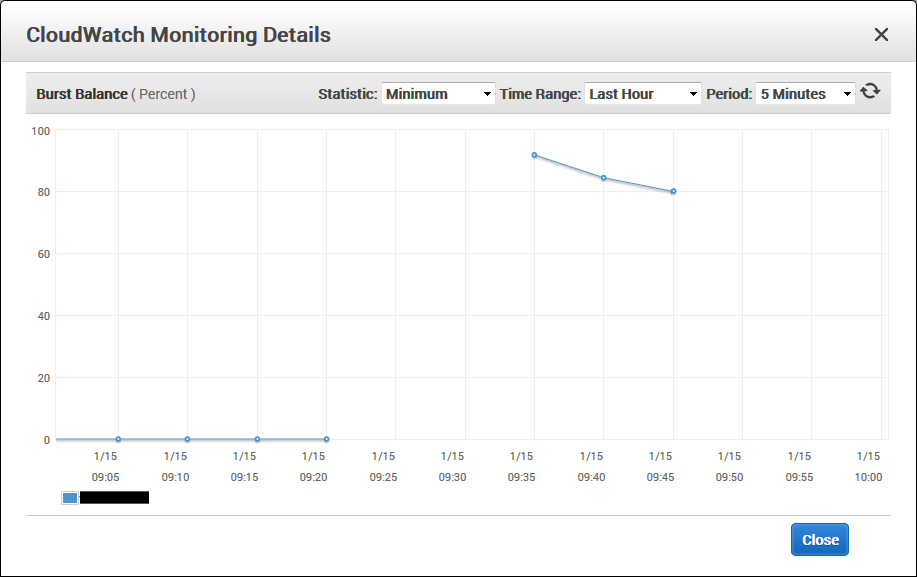
AWS EC2 Burst Balance
The Burst Balance went from 0% to 97% although it started declining immediately. Possibly pointing to the actual cause of the burst balance depletion.
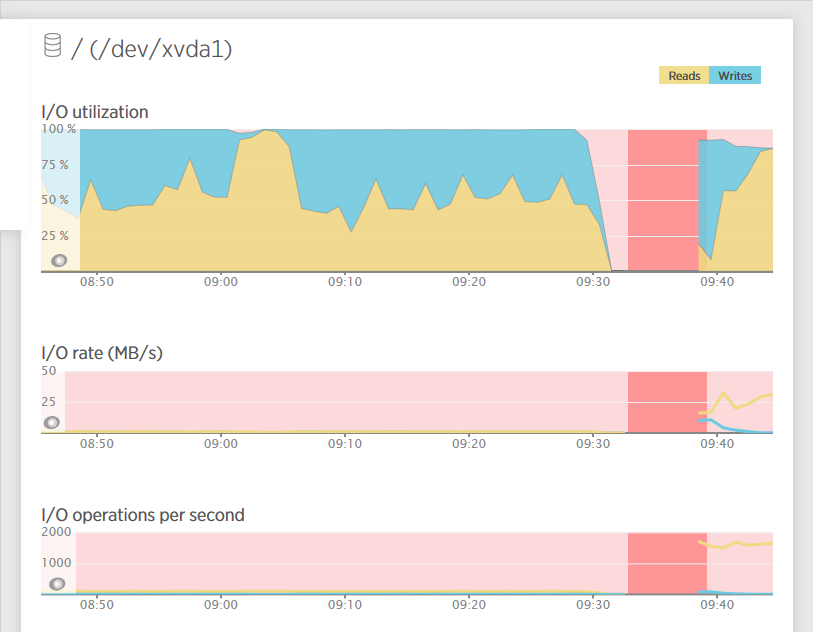
New Relic Disk Monitoring
Our New Relic metric also confirmed what we were seeing. Before the stop / start, I/O utilisation was 100%, roughly 50% in, 50% out but the I/O rate and I/O operations per second was nearly zero. After the stop / start the I/O utilisation was high which is fine because the I/O rate and I/O operations also increased.
Conclusion
The poor instance performance was a direct result of high write latency caused by the depletion of our available IOPS. Further investigation is required to see why that happened but having the option to stop / start the instance to renew the burst balance is invaluable to bringing the server back within normal operating standards quickly.
We have many years experience with Amazon Web Services, Linux administration and monitoring, server and website performance. If you would like to talk to us regarding AWS or Linux servers please feel free to contact us.


Leave a Reply
Want to join the discussion?Feel free to contribute!